最全视频数据集分享系列二 | 视频问答数据集
在当今数字化时代,人工智能已渗透到各个领域,成为推动技术革新和社会发展的关键力量。从早期的基于规则的简单算法,逐步演变为如今以深度学习为代表的复杂智能系统,人工智能的每一次重大突破都与数据的指数级增长和处理能力的飞跃紧密相连。而视频数据,作为一种信息密集且生动直观的数据源,在这一演进过程中扮演着至关重要的角色。随着视频数据的大量产生和广泛应用,视频理解技术变得越来越重要。它可以实现视频内容的自动分类、标注和检索,提高视频处理的效率和准确性,为各种应用提供有力支持,如视频监控、智能交通、影视制作、在线教育等领域。
视频数据集为大模型提供了丰富的时空信息,使模型能够学习物体运动、场景变化和事件发展等动态特征。高质量的视频数据集涵盖了多样化的场景、动作和情境,这有助于提高模型的泛化能力,使其在面对真实世界的复杂性时更加稳健。在文生视频等新兴任务中,全面而多样的视频数据集更是不可或缺,它们为模型提供了从文本到视觉序列的映射知识。
视频问答数据集概述
视频问答数据集是一种精心构建的多模态数据资源,它将视频片段与相关的文本问题及答案进行了有机整合。一个典型的视频问答数据集主要由以下几个关键部分组成:
- 视频片段:这些视频涵盖了广泛的领域和场景,包括但不限于日常生活记录、电影片段、新闻报道、教育讲座、体育赛事等。视频的时长、分辨率、帧率等参数因数据集的设计目的和应用场景而异。例如,在一些针对短视频理解的研究中,视频片段可能仅有几秒钟,且分辨率相对较低,以模拟社交媒体平台上常见的短视频形式;而在用于电影剧情分析的数据集里,视频片段则可能较长,且具有较高的画质,以便捕捉复杂的情节和细节。
- 问题文本:与视频相关的问题旨在测试机器对视频内容的各种理解能力,如物体识别、动作识别、事件推理、情感分析、语义理解等。问题的形式丰富多样,从简单的事实性询问(如 “视频中出现了几个苹果?”)到复杂的推理问题(如 “如果主角没有选择这条路,接下来的情节会怎样发展?”)。问题的语言表达也具有多样性,包括自然语言的各种句式和语法结构,这对模型的语言理解能力提出了很高的要求。
- 答案文本:针对每个问题,都提供了一个或多个准确的答案。答案的形式根据问题的类型而定,可能是简短的文本描述(如 “三个苹果”)、对视频中某个时间点或时间段的标注(如 “从视频的第 10 秒到第 20 秒”),甚至是复杂的逻辑推理结果(如 “主角可能会遇到另一个角色,然后引发新的冲突”)。
视频问答数据集在生成式 AI 模型训练中的关键作用
多模态信息融合的学习基础
生成式 AI 模型旨在能够生成连贯、合理且与输入信息相关的回答。对于视频问答任务,模型需要同时处理视频中的视觉信息和问题中的文本信息,并将两者进行有效的融合。视频问答数据集为模型提供了大量的多模态样本,使得模型能够学习到视觉特征与文本特征之间的映射关系。通过对数据集中众多视频片段和问题对的学习,模型逐渐掌握如何从视频的画面、颜色、动作等视觉元素中提取关键信息,并与问题中的语义信息相结合,从而生成准确的回答。例如,在一个关于动物行为的视频问答数据集中,模型通过反复学习视频中动物的动作、姿态以及对应的问题和答案,能够学会识别不同动物的行为模式,并根据问题准确描述动物正在做什么或者接下来可能会做什么。
语义理解与推理能力的培养
数据集中丰富多样的问题类型促使生成式 AI 模型不断提升其语义理解和推理能力。从简单的基于事实的问题到复杂的因果关系、逻辑推理和情感分析问题,模型在学习过程中逐渐掌握语言的语义结构和逻辑规则。以一个包含人物情感分析问题的数据集为例,模型通过分析视频中人物的表情、动作、语言以及上下文信息,结合问题中对情感的询问,学习如何推断人物的情感状态,如快乐、悲伤、愤怒等。这种推理能力的培养不仅有助于回答视频问答任务中的复杂问题,还能够迁移到其他自然语言处理任务中,提升模型的通用智能水平。
语言生成能力的优化
在回答视频问答任务时,生成式 AI 模型需要生成清晰、准确且符合语法和语义规范的文本答案。视频问答数据集为模型提供了丰富的语言生成训练素材,通过对大量问题和答案的学习,模型能够掌握不同类型问题的回答方式和语言表达方式,提高语言生成的流畅性和准确性。同时,数据集中答案的多样性也促使模型学会根据不同的视频内容和问题情境灵活生成合适的回答,避免生成过于单一和模式化的答案,从而提高模型回答的质量和实用性。
视频问答数据集
1. MSRVTT-QA
- 发布团队:微软研究院
- 发布时间:2016 年
- 下载链接:https://github.com/xudejing/video-question-answering
- 数据集大小:包含约 10,000 个视频剪辑,每个视频配有大约 20 个问答对,总计约 200,000 个问答实例。
- 数据集介绍:该数据集基于 MSR-Video-to-Text(MSRVTT)数据集构建,视频内容涵盖了日常生活场景、体育、新闻等多个领域。问题主要涉及视频中的人物、物体、动作和事件等方面,是视频问答研究领域中较为早期且具有代表性的数据集。数据集中的视频时长较短,平均在 10-20 秒左右,这使得模型在处理相对简洁的视频内容时能够更加聚焦于关键信息的提取和理解,有助于研究短视频问答技术以及模型在有限信息下的推理和回答能力。
2. TGIF-QA
- 发布团队:哥伦比亚大学(Columbia University)
- 发布时间:2018 年
- 下载链接:https://github.com/YunseokJANG/tgif-qa
- 数据集大小:包含大约 165,000 个视频问答对,视频来自于 TGIF(Tumblr GIF)数据集。
- 数据集介绍:TGIF-QA 数据集主要包含大量的动画 GIF 格式的短视频,具有独特的视觉风格和内容特点。专注于短视频(GIF 格式为主),问题类型包括动作识别、物体定位等。由于其视频长度较短且内容通常较为简单直观,该数据集对于研究模型在处理简单视觉场景下的快速理解和回答能力非常有帮助,同时也为开发轻量级、高效的视频问答模型提供了合适的训练数据,尤其适用于资源受限的应用场景,如移动设备上的视频问答应用。

3. MovieQA
- 发布团队:University of Southern California
- 发布时间:2016 年
- 下载链接:http://movieqa.cs.toronto.edu/
- 简介:MovieQA 数据集包含约 14,000 个问题,涉及 408 部电影,涵盖了不同类型的电影,包括剧情片、喜剧片、动作片、科幻片等,具有丰富的电影题材和风格多样性。MovieQA 数据集以电影内容为基础。问题包括电影情节、人物关系、场景细节等方面。它为电影领域的视频问答提供了丰富的素材,有助于研究电影理解相关的生成式 AI 模型。

4. TVQA
- 发布团队:佐治亚理工学院
- 发布时间:2019 年
- 下载链接:https://github.com/jayleicn/TVQA
- 简介:TVQA 包含超过 21,000 个问题,对应的视频来自 6 个热门电视剧,涵盖了不同类型的电视剧,如情景剧、悬疑剧、历史剧、科幻剧等,具有连贯的剧情和丰富的人物关系。问题涵盖了电视剧情节、人物情感、对话含义等多个方面。由于电视剧具有较长的剧情线和复杂的人物互动,这个数据集对于研究生成式 AI 模型在长期剧情理解和问答方面的能力很有帮助,例如在智能电视交互系统中,用户可以随时对正在观看的电视剧提出问题,模型能够根据剧情上下文提供准确的回答,提升用户的观看体验;同时也为电视剧的剧情分析、观众反馈预测等研究提供了数据支持。
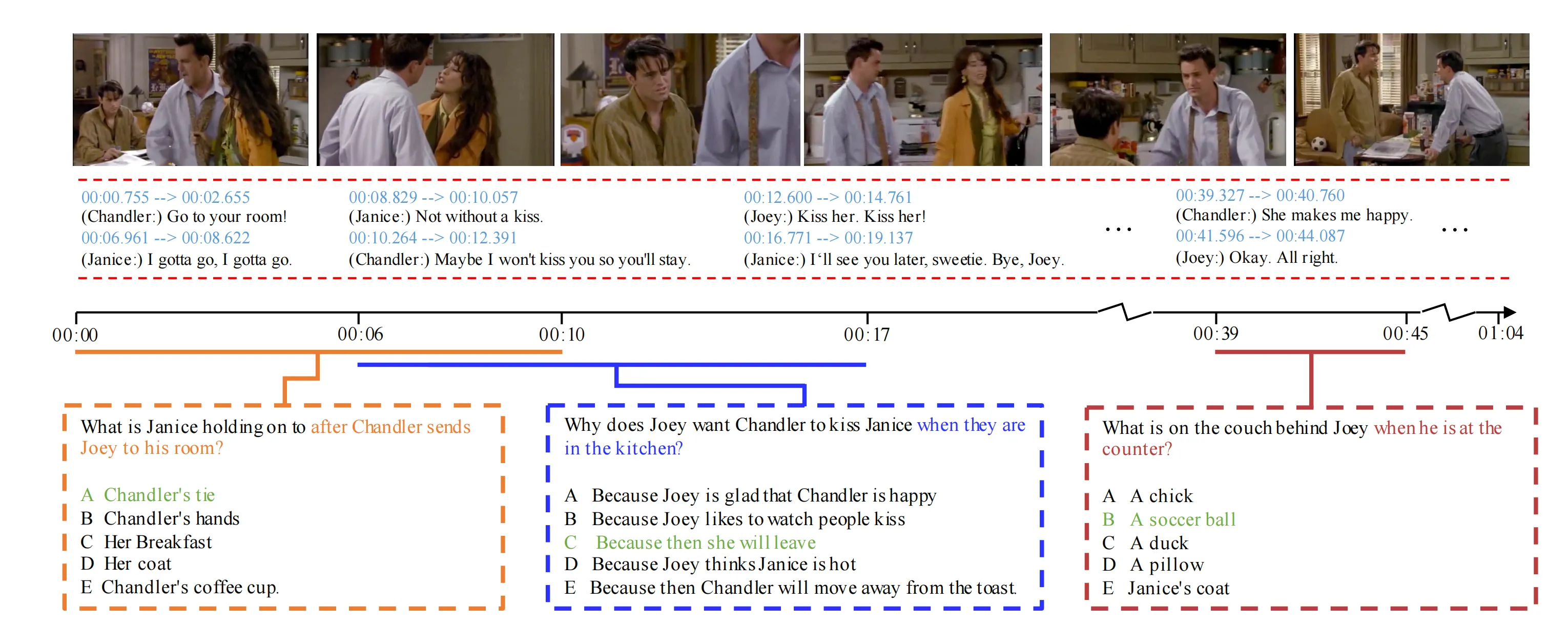
5. CLEVR-Dialog(Video-based)
- 发布团队:Facebook AI Research
- 发布时间:2019 年
- 下载链接:https://github.com/satwikkottur/clevr-dialog
- 简介:CLEVR-Dialog(Video - based)数据集使用合成视频,视频中的物体和场景是通过程序生成的,具有高度的可控性和可重复性,便于研究人员对特定的视觉元素和问题类型进行深入研究。该数据集主要用于研究模型的推理能力和对合成视频的问答性能。问题主要涉及逻辑推理和视觉元素的关系,如空间关系推理、属性推理、事件推理等。通过在这个数据集上的训练,模型能够在受控的环境中学习到精确的推理规则和逻辑关系,对于提升模型的推理能力和在复杂视觉推理任务中的表现具有重要意义,同时也为开发具有强大推理能力的生成式 AI 模型提供了有力的支持,在虚拟现实、游戏智能交互等领域具有潜在的应用前景。

6. AGQA
- 发布团队:华盛顿大学
- 发布时间:2021 年
- 下载链接:https://agqa.cs.washington.edu/
- 数据集大小:包含约 9.6 万个视频,超过 15 万个问题及相应答案。
- 简介:研究团队从网络上收集了大量不同类型的视频,涵盖了各种现实生活中的场景和事件等,如家庭活动、户外运动等。AGQA 通过人工标注和自动生成相结合的方式创建问题,这些问题旨在测试模型对视频内容的理解和推理能力,包括对动作、事件、物体、属性等多方面的提问,例如 “视频中的人在做什么之前先打开了门?”。AGQA 数据集的问题具有较高的复杂性和多样性,需要模型具备较强的逻辑推理和语言理解能力才能准确回答。它涵盖了多种语义类型的问题,如因果关系、时间顺序、动作意图等,为研究视频问答系统的推理能力提供了丰富的素材。同时,该数据集提供了详细的标注信息,包括问题的类别、答案的类型等,方便研究者对模型的性能进行深入分析和评估,有助于推动视频理解和问答技术的发展,使模型能够更好地应对真实世界中复杂的视频内容理解任务。
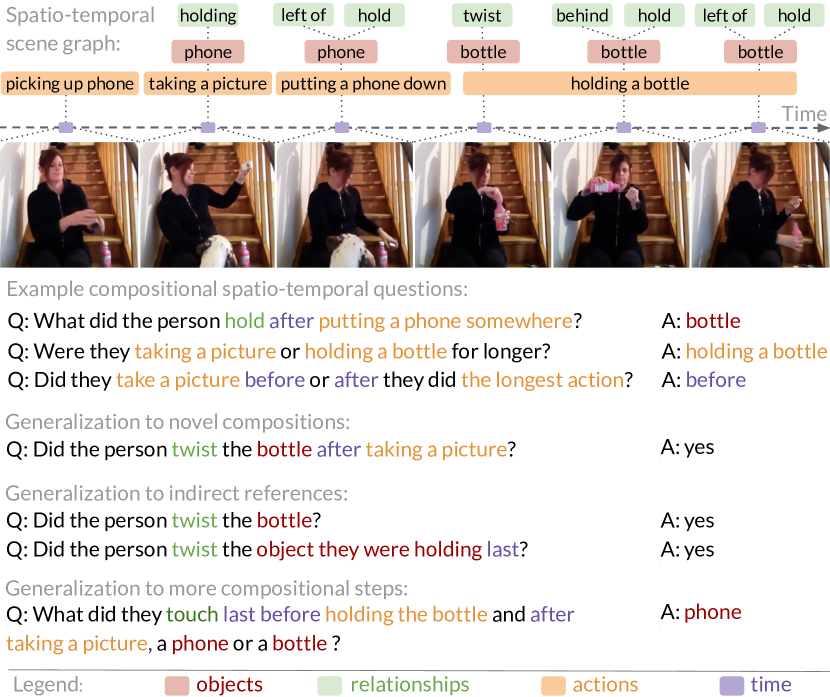
7. HowToVQA69M
- 发布团队:中科大、上海人工智能实验室等组成的 ShareGPT4V 团队
- 发布时间:2024 年
- 下载链接:https://antoyang.github.io/just-ask.html
- 数据集大小:包含 6900 万个视频-问题-答案三元组,视频总时长约 480 万小时。
- 简介:研究团队从网络上收集了大量视频数据,并利用 GPT-4v 的视觉能力对视频进行标注,得到了 4 万条(共 291 小时)带有标注的视频数据。在此基础上,通过自动生成视频描述的模型将数据规模拓展到了 6900 万条。问题围绕视频中的各种内容展开,包括动作、场景、物体、事件等多方面。HowToVQA69M 数据集的显著特点是其规模庞大,能够为模型训练提供丰富的数据资源。其生成的描述包含了丰富的世界知识、对象属性、摄像机运动,以及详细和精确的事件时间描述,有助于提升模型对视频内容的深度理解。此外,数据集中问题的复杂性和多样性较高,涉及多种语义类型的问题,如因果关系、时间顺序、动作意图等,可以有效推动视频问答系统推理能力的发展,使模型能够更好地应对真实世界中复杂的视频理解任务。同时,该数据集的标注信息较为详细,方便研究者对模型性能进行深入分析和评估,为视频相关的多模态理解和生成研究提供了有力支持。

整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MooreData Platform)与数据集构建服务(ACE Service),满足了智能驾驶、AIGC等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。

目前公司已合作海内外顶级科技公司与科研机构客户1000余家,拥有知识产权数十项,通过ISO9001、ISO27001等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。

 浙公网安备33010902003900
浙公网安备33010902003900