最全3D生成数据集分享系列|基于文本生成(Text-to-3D)的3D生成数据集
随着人工智能和计算机图形学的飞速发展,3D生成技术在虚拟现实(VR)、增强现实(AR)、游戏开发、电影特效以及机器人等领域得到了广泛应用。近年来,基于文本生成的3D数据集作为一种新的研究方向,吸引了大量的关注。本文最全3D生成数据集分享系列的第一篇,在这个系列中,我们将为大家整理介绍最全的核心3D生成开源数据集,供感兴趣的人进行研究参考。本文将详细探讨基于文本生成的3D数据集的概念特点,以及整理分享文本生成的重要开源数据集。
基于文本生成的3D数据集概述
基于文本生成的3D数据集是指通过自然语言文本描述生成三维物体、场景或结构的数据集。这些数据集通常由大量的物体或场景的文本描述组成,每条文本描述通常包含了关于物体外观、形状、尺寸、颜色、材质等多种特征的信息。利用这些文本信息,模型可以生成与之对应的三维数据,例如3D模型、点云、体素网格等。
基于文本生成的3D数据集提供了一个结合自然语言理解、计算机视觉、计算机图形学的跨学科研究平台。在文本描述到3D图像的转换过程中,大模型不仅需要理解文本的语义,还需要将文本转化为3D空间中的实际表现形式,因此,基于文本生成的3D数据集不仅挑战了计算机对自然语言的理解能力,同时也推动了3D图像生成技术的发展。基于文本生成的3D数据集,具有以下特点:
跨领域融合:基于文本生成的3D数据链接了自然语言处理(NLP)和计算机图形学(CG)的两个领域。生成3D物体的过程不仅要求模型理解文本中的细节,还需要精准地根据文本描述将这些细节映射到三维空间中,涉及的技术包括深度学习、图像生成、三维建模等。
丰富的语料库:与传统的3D数据集相比,基于文本生成的3D数据集在描述上具有更大的自由度。通过自然语言,研究人员可以灵活地对物体或场景进行描述,这为生成具有复杂结构和语义的三维物体提供了更丰富的语料库。
多样化输出:基于文本生成的3D数据集通常不仅限于生成传统的3D模型,还可以生成点云、体素网格、深度图、3D纹理贴图等多种不同类型的三维数据。这种多样性使得数据集在不同应用场景中具有广泛的适用性,不仅局限于物体生成,还可以应用于复杂的场景重建、虚拟环境创建、增强现实等更多领域。
基于文本生成的3D开源数据集
随3D生成研究的深入,目前各大高校与研究机构等,已经公开了许多成熟的开源数据集,致力于推动基于文本生成的3D技术发展。我们为大家整理了重要的基于文本生成的3D数据集,为大家进一步了解和使用基于文本生成的3D技术提供参考。
ShapeNet
- 发布方:Princeton University
- 下载地址:https://shapenet.org/about
- 发布时间:2015年发布
- 大小:约50GB(包含多个类别和3D模型)
- 简介:ShapeNet是目前最广泛使用的3D物体数据集之一,包含超过5000个物体类别,超过30万个3D模型,涵盖了从家具、交通工具到自然物体等各种类别。它不仅为研究3D物体识别和生成提供了大量数据,还为深度学习和计算机视觉领域提供了一个重要的基准数据集。ShapeNet中的模型数据采用了标准的3D文件格式(如.obj),并且包含丰富的标签信息,如物体类别和子类别。该数据集已经成为3D生成、分割、识别、检索等领域的研究基准。
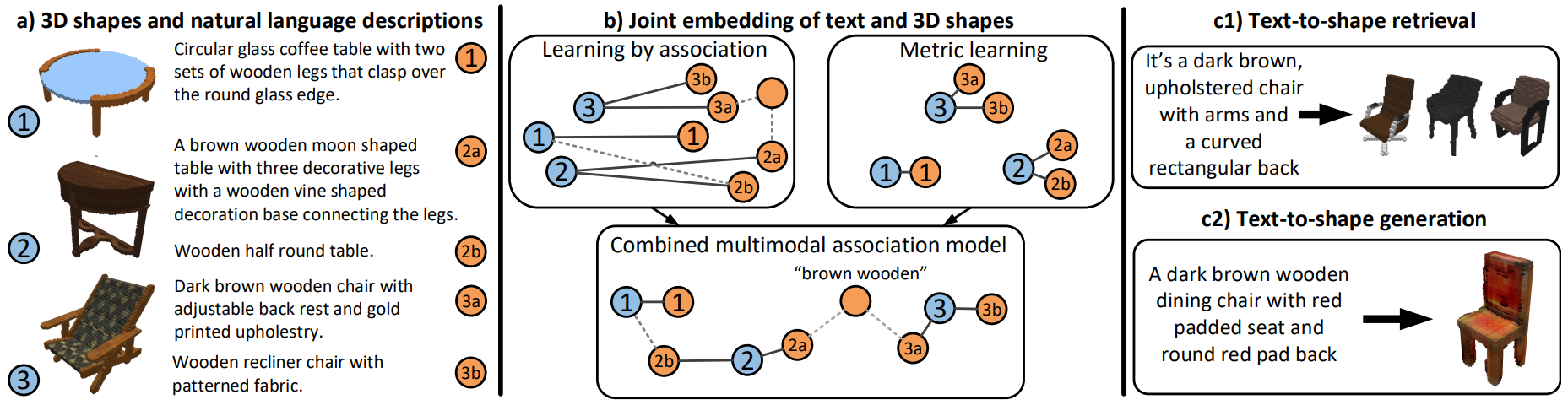
Text2Shape
- 发布方:University of California, Berkeley
- 下载地址:http://text2shape.stanford.edu/
- 发布时间:2016年发布
- 大小:约2GB
- 简介:Text2Shape是一个基于文本生成三维物体的数据集,包含了自然语言描述和相应的3D模型。每个三维模型都配有详细的文本描述,描述内容涵盖了形状、颜色、材质等信息。Text2Shape数据集的目标是研究如何从给定的文本描述中生成符合要求的三维形状。它为文本到3D生成的研究提供了一个丰富的实验平台,尤其是在利用深度学习生成三维模型的研究中具有重要地位。
3D-COCO
- 发布方:UC Berkeley, Facebook AI Research
- 下载地址:https://kalisteo.cea.fr/index.php/coco3d-object-detection-and-reconstruction/
- 发布时间:2017年发布
- 大小:约6GB(包含3D模型和图像描述数据)
- 简介:3D-COCO是基于著名的COCO数据集构建的一个3D数据集,主要针对基于图像的3D物体重建和生成任务。该数据集结合了COCO图像数据集的标注和3D重建信息,提供了图像和3D模型的关联数据。3D-COCO包含大量的物体类别,并且为每个图像提供对应的3D物体、场景信息以及点云数据,旨在帮助研究者进行多模态学习、图像到3D的转换等任务。该数据集的推出,促进了3D计算机视觉领域的发展,并成为多模态学习的一个重要资源。
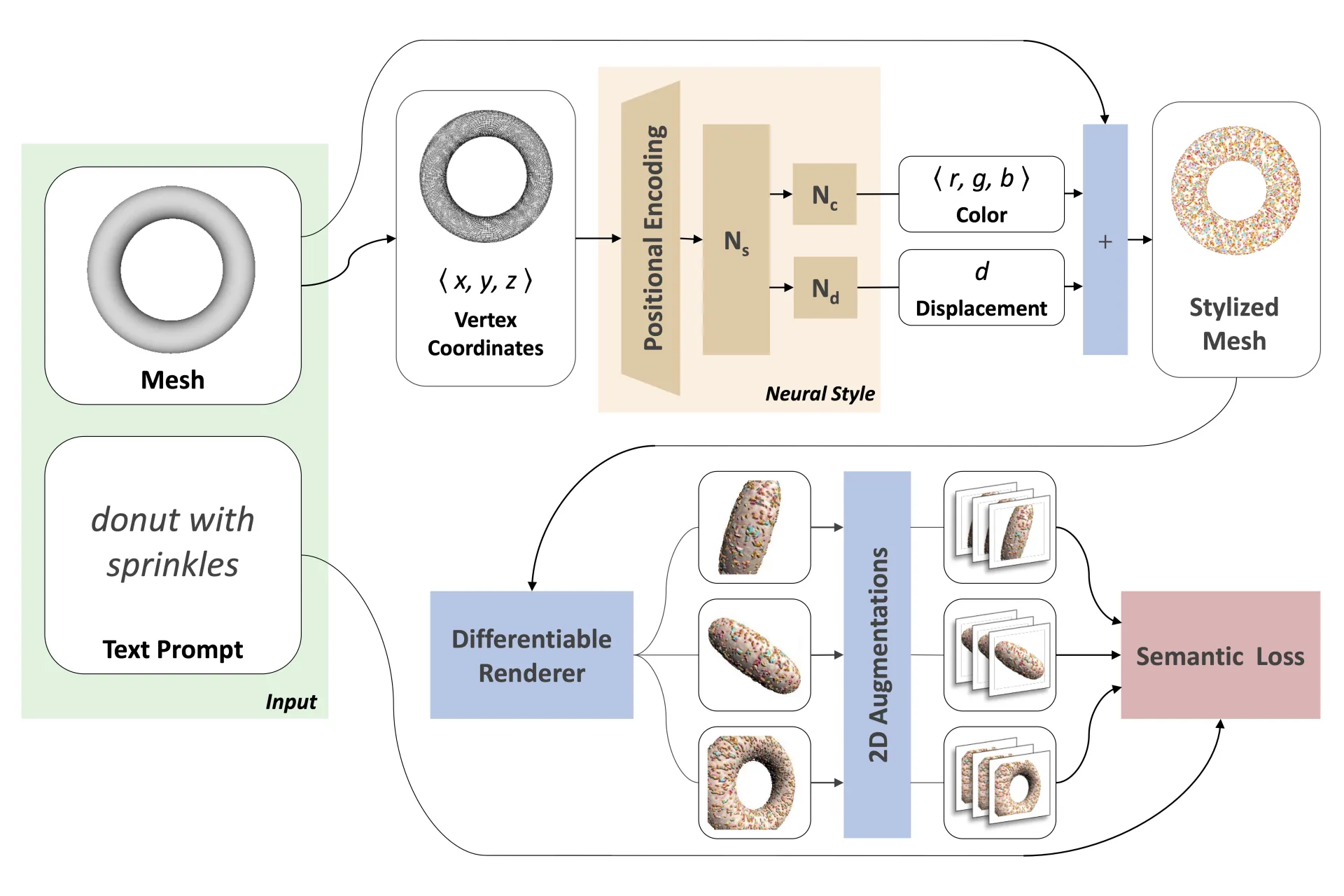
Text2Mesh
- 发布方:University of California, Berkeley
- 下载地址:https://threedle.github.io/text2mesh/
- 发布时间:2019年发布
- 大小:约5GB(包含文本描述和网格数据)
- 简介:Text2Mesh是一个旨在通过文本描述生成3D网格模型的数据集。该数据集包含了不同物体的详细文本描述,并将这些描述与网格数据相结合,构建出对应的三维网格。Text2Mesh特别适合于需要生成具有详细几何形状的三维模型的任务,涵盖了多个物体类别,包括但不限于家具、交通工具等。它对于研究如何从自然语言描述中推导出精确的三维几何形状具有重要意义。
Text2Room
- 发布方:MIT Computer Science and Artificial Intelligence Laboratory (CSAIL)
- 下载地址:https://lukashoel.github.io/text-to-room/
- 发布时间:2020年发布
- 大小:约12GB(包含3D房间模型和对应的文本描述)
- 简介:Text2Room是一个专门用于生成室内场景的开源数据集。它提供了大量的房间布局、家具和物体的3D模型以及它们的文本描述。数据集中的文本描述涉及房间的结构、家具摆放、物体的位置等,研究人员可以用这些描述来生成房间的三维模型。Text2Room主要应用于室内设计、虚拟现实和增强现实等领域,推动了基于文本的室内3D建模技术的发展。

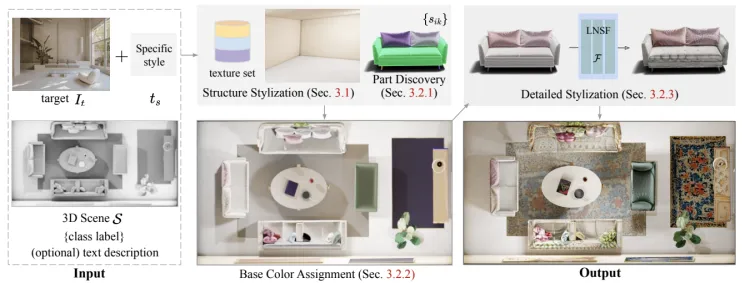
Text2Scene
- 发布方:University of Washington
- 下载地址:https://openaccess.thecvf.com/content/CVPR2023/html/Hwang_Text2Scene_Text-Driven_Indoor_Scene_Stylization_With_Part-Aware_Details_CVPR_2023_paper.html
- 发布时间:2019年发布
- 大小:约10GB(包含3D场景和文本描述)
- 简介:Text2Scene是一个面向3D场景生成的数据集,旨在从自然语言描述中生成复杂的三维场景。这些场景包括多个物体、不同的环境、布局以及它们之间的交互。每个场景都附带有详细的文本描述,涵盖了物体的类别、位置、颜色等信息。该数据集的重点在于生成符合场景描述的多个物体和它们的空间关系,广泛应用于自动化场景生成、增强现实和智能空间构建等研究领域。
这些数据集不仅涵盖了物体、房间、几何形状等多种类型的3D数据,还提供了与之对应的自然语言描述,帮助研究人员探索如何将复杂的文本信息转化为三维空间中的实际对象。除了上述开源数据集外,整数智能同样具有丰富的基于文本生成的3D数据集储备,同时也可以根据特殊需求和场景提供定制化的数据集建构服务,致力于帮助学界和业界更好地理解和开发更高效、更精确的文本到3D生成模型。
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MooreData Platform)与数据集构建服务(ACE Service),满足了智能驾驶、AIGC等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。

目前公司已合作海内外顶级科技公司与科研机构客户1000余家,拥有知识产权数十项,通过ISO9001、ISO27001等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。

 浙公网安备33010902003900
浙公网安备33010902003900