最全3D生成数据集分享系列|基于图像生成(Image-to-3D)的3D生成数据集
在上一期《最全3D生成数据集分享系列》中,我们介绍与分享了基于文本生成的3D生成数据集,并整理了相关的重要开源数据集。这一期3D生成数据集系列分享中,我们将介绍分享基于图像生成的3D生成数据集。
基于图像生成的3D数据集概述
基于图像生成的3D数据集是指通过输入2D图像或图像序列生成对应的三维物体、场景或结构的3D数据集。这些数据集通常包含大量的图像和与之对应的3D模型、点云、体素网格、深度图等三维数据。基于图像生成的3D数据集利用计算机视觉和图形学技术,将平面图像中的信息提取出来,重建物体或场景的三维结构。这一过程通常包括从图像中的二维信息恢复深度信息,生成三维空间中的物体或场景。
这些数据集为深度学习和计算机图形学领域的研究提供了极其重要的资源。通过基于图像生成3D模型,研究者能够探索如何从单张或多张图像中推断出物体的空间布局、深度信息以及3D形状等。与基于文本生成的3D数据集类似,基于图像生成的3D数据集在推动计算机视觉、三维重建、虚拟现实(VR)、增强现实(AR)等应用领域的发展中,起到了关键性作用。
基于图像生成的3D数据集具有以下特点:
计算机视觉与图形学的结合:基于图像生成的3D数据集连接了计算机视觉和计算机图形学两个领域。生成3D模型的过程不仅要求模型能够理解和分析二维图像中的信息,还要能够推断出与这些图像对应的三维空间布局和深度信息。这就需要涉及深度学习、三维建模、几何重建等多个技术领域。
深度恢复与三维建模:与基于文本生成的3D数据集不同,基于图像生成的3D数据集更加注重从二维图像中恢复物体的深度信息。这要求模型具备强大的空间推理能力,能够从多个视角的图像中综合判断物体的三维形状和结构。随着深度学习技术的进步,这类数据集成为了训练深度神经网络以解决三维重建问题的重要基础。
多模态数据输出:和基于文本生成的3D数据集一样,基于图像生成的3D数据集通常不仅提供了传统的3D模型,还可以生成点云、体素网格、深度图、3D纹理贴图等多种形式的三维数据。这种多样化的输出使得数据集能够在不同的应用场景下,如自动驾驶、机器人导航、虚拟现实和游戏开发等,得到广泛的应用。
基于文本生成的3D开源数据集
以下是一些重要的基于图像生成3D数据集的整理与介绍:
Pix3D
- 发布方:UC Berkeley
- 下载地址:https://github.com/xingyuansun/pix3d
- 发布时间:2017年
- 大小:约30GB(包括图像和3D模型)
- 简介:Pix3D是一个用于从单幅图像生成3D物体模型的数据集。该数据集包含了来自多个物体类别的图像和相应的三维模型,旨在推动图像到3D物体生成技术的发展。每个图像都提供了与之对应的3D模型,该模型由多视角的二维图像推导出来。Pix3D的数据集非常适用于单图像三维重建任务,尤其在训练深度学习模型进行图像到3D转换方面具有重要的应用价值。
3D-R2N2
- 发布方:Princeton University
- 下载地址:https://cvgl.stanford.edu/3d-r2n2/
- 发布时间:2016年发布
- 大小:约40GB(包含图像、3D模型和深度信息)
- 简介:3D-R2N2是一个基于多视角图像生成3D物体的数据集,主要用于研究如何从多个2D图像中恢复物体的3D形状。该数据集包含了丰富的3D物体模型以及来自不同视角的图像,且每个模型都提供了深度信息。3D-R2N2的数据集尤其适用于多视角图像到3D模型的生成,推动了三维重建技术的研究和应用。
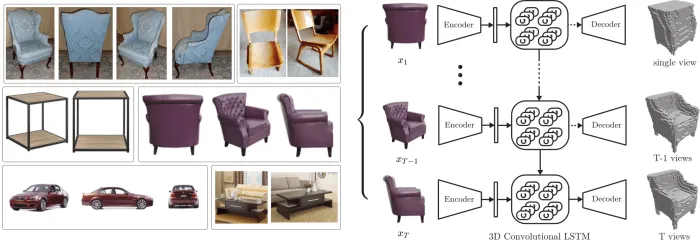
Multi-View 3D Object Detection (MV3D)
- 发布方:University of California, Berkeley
- 下载地址:https://github.com/bostondiditeam/MV3D
- 发布时间:2017年
- 大小:约50GB(包含3D模型、图像和标签数据)
- 简介:MV3D是一个针对3D物体检测的数据集,旨在通过多视角图像生成完整的3D物体模型。该数据集的目标是通过深度学习技术,实现从多个视角的图像中准确地生成和识别三维物体。MV3D的数据集不仅提供了丰富的三维物体标注数据,还包含了通过传感器(如激光雷达)获得的深度信息,适用于自动驾驶和机器人导航等领域的研究。
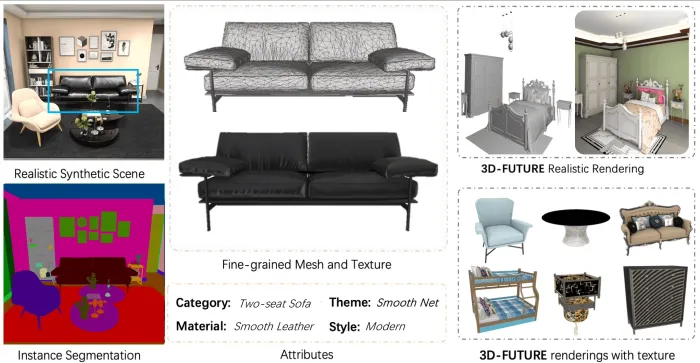
3D-FUTURE
- 发布方:Alibaba-inc, ICT.CAS, University of Melbourne, Birkbeck College, University of London, The University of Sydney
- 下载地址:https://www.3d-future.com
- 发布时间:2021
- 大小:约100GB(包括图像、3D模型、纹理等)
- 简介:3D-FUTURE(3D FUrniture shape with TextURE)是一个用于研究三维家具模型生成、纹理恢复及迁移的大型开源数据集。该数据集包含了20,240张逼真的合成室内图像,拍摄自5000多个多样化的场景,并且提供了9,992个独特的工业级家具3D CAD模型,这些模型由专业设计师制作,并附带高分辨率的纹理信息。
ScanNet
- 发布方:Stanford University & UC Berkeley
- 下载地址:https://www.scan-net.org/
- 发布时间:2017年
- 大小:约800GB
- 简介:ScanNet是一个大规模的室内3D场景数据集,包含了丰富的RGB-D图像和相应的三维重建模型。ScanNet数据集支持多种任务,包括三维场景重建、语义分割、物体检测、图像到3D生成等。每个场景都包含丰富的标注信息,如语义标签、深度信息等。ScanNet在学术界得到了广泛应用,是图像到3D生成研究中的重要数据集之一。它的高质量标注和大规模数据使得它成为了三维重建和场景理解领域的重要参考。

Matterport3D
- 发布方:Matterport, Stanford University
- 下载地址:https://niessner.github.io/Matterport/
- 发布时间:2017年发布
- 大小:约200GB(包括3D模型、图像和点云数据)
- 简介:Matterport3D是一个室内空间重建数据集,提供了大量通过Matterport相机拍摄的3D室内场景数据。该数据集包含了详细的3D模型、RGB图像、深度图和点云数据,适用于训练和测试基于图像的三维重建和空间感知模型。Matterport3D为室内场景理解、机器人导航、虚拟现实等领域提供了宝贵的资源。

ModelNet
- 发布方:Princeton University
- 下载地址:https://modelnet.cs.princeton.edu/
- 发布时间:2015年发布
- 大小:约2GB(ModelNet10);约30GB(ModelNet40)
- 简介:ModelNet是一个大规模的3D模型数据集,包含了来自127个物体类别的3D物体模型,其中ModelNet10包含10个类别,ModelNet40则包含40个类别。它适用于3D物体识别、分类、检索等任务。虽然ModelNet的主要目标是为物体分类提供数据支持,但也有研究基于该数据集进行图像到3D生成的实验。模型数据使用标准的3D模型文件格式(如.obj)存储,并提供了丰富的物体类别信息。

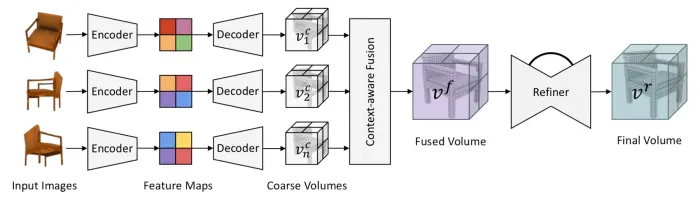
Pix2Vox
- 发布方:Peking University
- 下载地址:https://github.com/hzxie/Pix2Vox
- 发布时间:2019年发布
- 大小:约6GB
- 简介:Pix2Vox是一个用于图像到3D生成的数据集,包含了从多个视角拍摄的2D图像,并提供了相应的3D模型。该数据集支持基于多视角图像生成三维物体,是深度学习研究中的经典数据集之一。Pix2Vox的特点在于它不仅提供了图像到3D生成的任务,还支持基于多视角的三维重建,能够为图像到三维生成领域的研究提供有力支持。
基于图像生成的3D数据集为计算机视觉和图形学领域提供了极其重要的资源。这些数据集不仅帮助研究人员从图像中恢复三维信息,还推动了自动驾驶、机器人技术、虚拟现实等领域的应用。除了上述开源数据集外,整数智能同样具有丰富的基于文本生成的3D数据集储备,同时也可以根据特殊需求和场景提供定制化的数据集建构服务,通过这些数据集与服务,学界和业界可以在复杂的三维场景理解和生成任务上进行深入探索,推动三维重建技术的不断发展。
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据合伙人。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MooreData Platform)与数据集构建服务(ACE Service),满足了智能驾驶、AIGC等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。

目前公司已合作海内外顶级科技公司与科研机构客户1000余家,拥有知识产权数十项,通过ISO9001、ISO27001等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。

 浙公网安备33010902003900
浙公网安备33010902003900